长期以来,English无疑是AI领域的“官方语言”。从底层的代码注释,到顶层的论文发表,再到大模型的预训练语料,英文都占据了绝对的统治地位。互联网上英文语料的压倒性优势,让人们形成了一种惯性思维:想要得到最好的回答,就得用英文去提问;想要激发AI的最强推理能力,就得用英文写提示词。过往的研究也普遍认为,当大模型们使用高资源语言(通常是英语)进行推理时,会获得更高的准确率和token 效率。但事实真的是这样吗?
arxiv.org上有一篇关于大模型识别和利用汉字部首能力的论文,题为《The Impact of Visual Information in Chinese Characters: Evaluating Large Models’ Ability to Recognize and Utilize Radicals》。研究人员发现,大模型在处理中文时,其实不仅仅是在处理一个个抽象的编码,它们在一定程度上能够识别并利用汉字中的视觉信息,比如偏旁部首。
这就好比说,英文单词是线性的,像是一串密码;而汉字是二维的,每一个字都像是一个打包好的压缩包。比如看到“河”和“海”,哪怕不认识这两个字,光看“三点水”也能猜到它们跟水有关。这种原生的语义增强,是表音文字所不具备的。在AI眼中,汉字或许不只是文字,更像是一种高密度的特征向量。
如果说视觉信息还是理论上的优势,那么“省钱”就是实打实的工程红利了。
GitHub上有一个关于阿里Qwen3的名为llm-chinese-english的测试项目,非常详细地介绍了用Qwen3进行推理的测试过程,作者发现了一个惊人的数据:在进行同等质量的推理任务(Reasoning)时,中文比英文用了更少的词元,而且问题难度越高token节省得越多,5级难度的数学问题节省了47%的token用量。
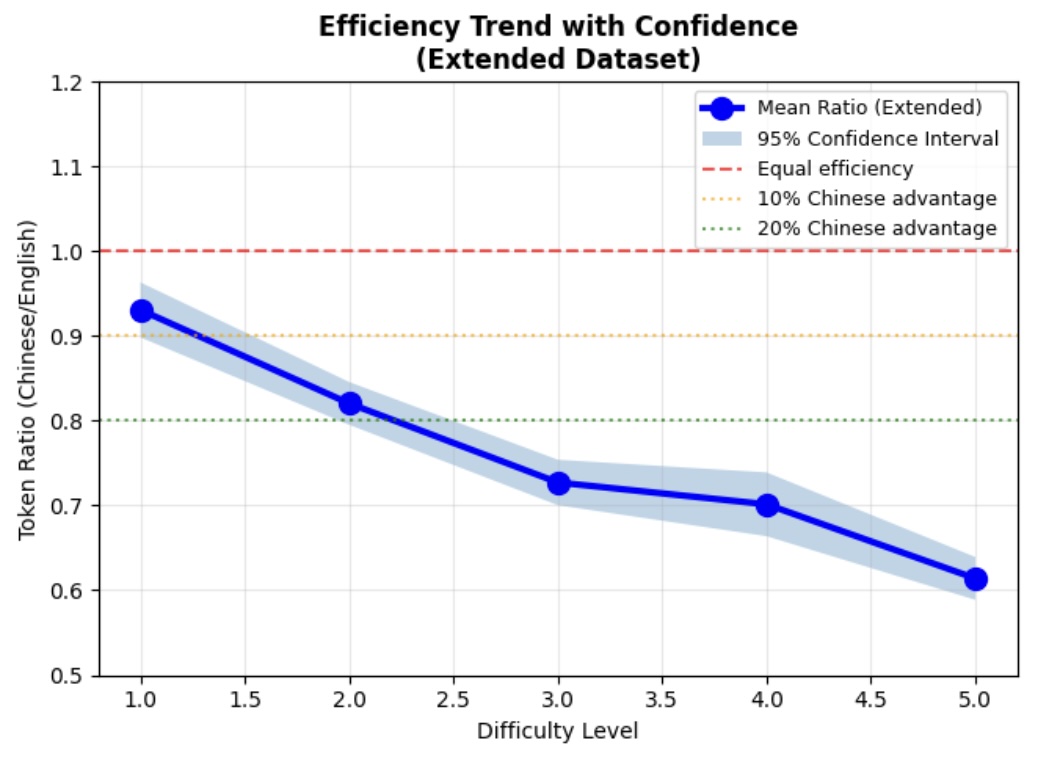
文中还提到:
-
英文在 77 个问题中触及 8K 词元上限(占比 15.4%)而失败,而中文全部完成。
-
当使用 16K 词元重新测试时,这 77 个英文失败案例中有 45 个成功(58%恢复率)
也就是在资源充足的情况下英文能达到与中文相当的准确度,但其词元消耗量比中文多出约 67%(即中文仅需英文约 60% 的资源消耗)。
在LLM的世界里,token就是金钱,就是时间。节省40%不仅意味着推理速度的大幅提升,更意味着推理成本的直接腰斩。
造成这种差异的原因,除了中文本身极高的信息密度——表达同样的意思中文往往只需要更少的字数——之外,文中还有一个有趣的发现:中文的思维链(CoT)往往更加直接和自信。相比之下,英文的推理过程往往充满了试探性的语句和自我修正,显得有些絮叨。这可能跟训练语料中两种语言背后的思维习惯有关。
无关语言的优劣比较,但信息密度等硬指标足以让我们重新审视中文在AI时代的地位。过去人们总觉得中文语料少、质量差,是AI发展的短板。但换个角度看,中文这种高密度、高熵值、且自带视觉语义辅助的语言,说不定才是最适合人机交互的“高阶语言”。
参加IMO、IOI这类国际奥林匹克竞赛是验证大模型能力的一种方式,目前有OpenAI、Gemini还有DeepSeek几个大模型达到了金牌级别。有朝一日把多个大模型放在一起比赛做题的话,假如能限定同样的算力,那么测量答案的正确性和花费的时间长短就能对大模型的推理能力得出非常准确的排名。如果使用中文推理花费token更少,速度更快,是不是大模型们都会选择用中文思考呢?
下次写复杂的Prompt时,不妨试试把“Think in English”改成“用中文思考”。毕竟,在这个算力为王的时代,谁能用更少的token把事情说清楚,谁就是赢家。